Reliable File System
Spodní vrstva
Dokumentace: Martin Dvořák
Co by nemělo ujít Vaší pozornosti:
Srdce spodní vrstvy CacheMan - pro pochopení toho jak spodní vrstva funguje je nutné si pročíst kapitolu o něm. CacheMan je nositelem mazanosti cache. CacheMan byl navržen tak, aby horní vrstva NEMUSELA vůbec LOGOVAT a také se nemusela v
ůbec starat o KONZISTENCI - vše je v něm zabudováno! Cacheman je interfacem mezi spodní a horní vrstou - je poskytovatelem služeb. Zásadní význam pro práci s ním má pojem package.
Další superdůležitou kapitolou je kapitola o TRANSAKCÍCH a LOGOVÁNÍ. Když už nic jiného tak tato kapitola ozřejmí proč nazývat náš file system RELIABLE.
Examply
Examply, které předvádějí spodní vrstvu jsou tyto projekty:
example1.prj, ( main v EXAMPLE1.LOW ) - vytvoření disků, oblastí, formátování
example2.prj, ( main v EXAMPLE2.LOW ) - dva examply na fungování CacheMana
example3.prj, ( main v EXAMPLE3.LOW ) - transakce, logy a recovery spodní vrstvy
example4.prj, ( main v EXAMPLE4.LOW ) - striping a záchrana disku
Všechny informace k tomu kterému examplu jsou v jeho main.cpp. Tam najdete co example provádí, co máte udělat...
Obsah
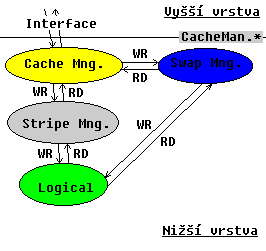
Schema spodní vrstvy file systému
Jak již bylo zmíněno interfacem mezi horní a spodní vrstvou je Cacheman. Horní vrstva volá při obvyklé práce vlastně pouze jeho funkce. Ty jsou dekladrovány v CACHEMAN.H
Struktura dat na disku
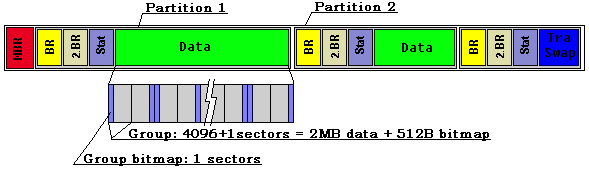
Nyní podrobněji k jednotlivým strukturám...
Master Boot Record
Master boot record má klasický formát. Jeho velikost je 1 sektor == 512B. Vyhrazena je pro něj ale celá první stopa. Pro větší bezpečnost při každé změně MBR duplikujeme jeho obsah do všech sektorů první stopy. V případě havárie tedy může záchranná utili
ta s velkou pravděpodobností MBR restaurovat.
Formát Master boot recordu je deklarován v FSTYPES.H
Boot Record
Zabírá jeden sektor. Obsahuje klasické informace. Struktura ne nepodobná MBR. Oproti MBR obsahuje informace důležité pro oblast:
- Dirty flag oblasti: je TRUE pokud oblast nebyla čistě uzavřena. Tento flag se kontroluje při startu systému. Pokud je oblast dirty nastartuje se záchranná a kontrolní utilita. Při uzavírání systému se nastavuje na FALSE.
- Adresa FNODU root recordu v oblasti ( adresa logická, relativní od začátku oblasti ).
- Počet grup v oblasti.
- ...
Formát Boot recordu je deklarován v FSTYPES.H
The Second Boot Record
Je rozšířením + částečnou zálohou Boot Recordu. Obsahuje kopii BIOS parametr bloku
boot recordu -> ten obsahuje nejdůležitější informace důležité pro orientaci v oblasti
( bez nich se to dá v podstatě zabalit ). Dále obsahuje statistické informace jako: počet volných sektorů v oblasti, počet sektorů se statistikou grup ( viz níže ), duplikát počtu grup v oblasti, label oblasti. The Second Boot Record není bezpodmíněčně
nutný pro běh RFS. Informace z něj využívají funkce pro alokace/dealokace sektorů. Jeho výpadek není fatální.
Formát The Second Boot recordu je deklarován v FSTYPES.H
Statistika grup
Je to oblast několika sektorů, která udržuje informaci o tom kolik je v každé grupě v oblasti volných sektorů ( Word ). Každý sektor tedy obsahuje informace o 512/2 grupách, počet statistických sektorů se řídí počtem grup. Tyto statistiky jsou spravován
y a využívány funkcemi CacheManAllocateSector a CacheManFreeSector z CACHEMAN.*. Funkce statistiku používají např. pro rychlé vytypování grupy pro alokaci.
Oblast ( myšlena partition )
Oblasti jsou číslovány od 1 do 4. Vytváření se provádí pomocí funkcí z FDISK.H
Limity uvnitř jedné oblasti:
Datová kapacita grupy v sektorech: 12b sektorů ... 4k * 512B = 2MB
Počet grup v oblasti: 20b ... 1M grup
Velikost grupy: 4k datových sektorů + 1 sektor bitmapa
Maximální adresovatelná velikost FS: 32b sektorů ... 4,3M * 512B = 2,2TB neboli 1M grup * 2MB velikost grupy = 2,2TB
Grupy
Data v oblastech jsou organizována v grupách.
-
Grupa se skládá z bitmapy ( 1 sektor )a datových sektorů ( 4096=512*8 sektorů ). Bitmapa informuje o obsazení sektorů v grupě: BIT: 1..sektor je volný, 0..sektor je plný. Umístěna je u sudých grup na počátka a u lichých na konci => tím vzniká souvislý
datový prostor délky 4MB.

-
Čísla týkající se grup:
Datová kapacita grupy v sektorech: 12b sektorů ... 4k * 512B = 2MB
Počet grup v oblasti: 20b ... 1M grup
Velikost grupy: 4k datových sektorů + 1 sektor bitmapa
-
Poslední grupa v oblasti vyjde zpravidla neúplná. Při formátování ji vytvořím - vytvořím hlavičku, verify sektory, do hlavičky poznačím sektory které v grupě chybí ( za koncem oblasti ) jako plné. Později ji tedy lze použít. Nyní je, ale implementace tak
ová, že se poslední grupa nepoužívá vůbec. Proč ji nepoužívám:
-
Při každém zápisu či čtení musí být test zda to není poslední grupa. Do té se přistupuje jinak - ať lichá či sudám má bitmapu vždy na počátku - velmi to zpomalovalo.
-
může mít velikost do 1 do 4096 sektorů a tak se mi může stát, že budu mít pouze sektor na bitmapu. Kdybych ji chtěl používat na nějaké servisní informace opět nevím co vše by se tam dalo uložit.
-
Jak se vyrovnávám s BADSEKTORY...
-
Vyskytnou-li se při formátování: sektor se označí v hlavičce bitmapy jako zaplněný. Vyšší vrstva si ho nealokovala ... nemůže tedy o něj požádat a nižší vrstva si myslí, že je plný a tak ho nikomu nedá ... tak se sektor nepoužívá.
-
Vyskytnou-li se za běhu: řeknu vyšší vrstvě, že sektor se nepodařilo zapsat a já ho označím jako plný. Vyšší vrstva už to vyřídí ( pokusí se sektor zapsat jinam: naalokuje si jinde místo a zapíše ho tam ). Když to nastane při readu postupuje se obdobně p
ouze nahoru dodám co jsem na třikrát přečetl ( většina bude asi špatně protože CRC nesedlo, ale je lepší dodat něco než nic ).
-
Co se týče alokace sektorů v grupě:
-
Vyšší vrstva má možnost si říci za kterým sektorem a v které grupě má alokovaná oblast začínat - spodní vrstva se jí snaží vyhovět ( CacheManAllocateSector() CACHEMAN.H ).
-
PŘEDALOKOVÁVÁNÍ nechávám na vyšší vrstvě - ta si řekne o víc než chce a já jí takovou oblast dodám ( sám však nevím, jestli všechno využije nebo si syslí do budoucnosti ).
-
HLEDÁNÍ GRUPY VHODNÉ PRO ALOKACI: k dispozici je statistika zaplnění celé oblasti + jednotlivých grup ( viz. výše ). Pokud caller specifikoval, kde by měla alokovaná oblast začínat tak skouším hledat od tohoto sektoru v grupě dále. Pokud nic nenaj
du prohledám grupu od začátku až po specifikované místo. Pokud neuspěji ani teď hledám v následující grupě ( a tak eventuelně projdu všechny grupy oblasti ). Při hledání se hojně využívají statistiky ( než načtu bitmapu grupy ze statistiky zjistím zda to
má vůbec smysl).
Pokud caller nespecifikoval, kde má alokovaná oblast začínat - vystřelím do grup náhodně. A pak při hledání postupuji výše uvedeným způsobem. Funguje to celkem spolehlivě. Důvod proč to provádím je ten, že se file system zaplňuje rovnoměrně ( nealokuje s
e od počátku - data jsou roztroušena po disku ) a tak se snižuje pravděpodobnost fragmentace. Jakmile je místa méně, tak procházím statistiku a hledám podle ní. Velikosti děr v grupách si nepamatuji. Udržování takové informace by bylo jak časově tak pamě
ťově velmi náročné a podle mého názoru by se to ve výsledku ani nevyplatilo. Já v nejhorším případě musím navštívit více grup. Díky alokační strategii uvedené výše a statistikám se docela slušně orientuji a souvislé prázdné oblasti se zpravidla najdou. S
e zaplňováním filesystemu se vše samozřejmě zpomaluje.
Alokace provádí funkce CacheManAllocateSector() z CACHEMAN.H ).
-
Co grupy daly a co vzaly...
-
 Data jsou soustředěna více u sebe. Grupy jsou menší a tak pokud ztratíme jednu grupu nepřijdeme o tolik informací.
Data jsou soustředěna více u sebe. Grupy jsou menší a tak pokud ztratíme jednu grupu nepřijdeme o tolik informací.
-
Použití grup umožnilo zvolit jako alokační jednotku sektor ( ve smyslu úspornosti režijních informací ) a tím se zmenšil slack space.
-
 Udržování grup = bitmap něco stojí.
Udržování grup = bitmap něco stojí.
Funkce pro práci s grupami jsou deklarovány v GROUP.H, deklarece fcí provádějících alokace a dealokoce sektorů v CACHEMAN.H implementace je v ALLOCFRE.CPP.
Fyzické chyby media a jak jsme se s nimi vyrovnali
Velikosti postižené oblasti: chyby bitové, bytové jsme se rozhodli na úrovni filesystemu neošetřovat. Využívat budeme hardwarového zabezpečení. Každý disk má za sektorem 32 bitový ECC částečně samoopravný kód. Je tedy zbytečné zajišťovat data lepším kóde
m apod. Menší chyby bitového rázu ( tuším do 4B ) by tedy měl opravit hardware.
Striping
My jsme se rozhodli pro ochranu na úrovni sektorů a to metodou STRIPINGU. Data jsou na discích rozložena takto:
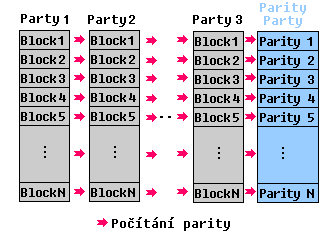
Jak je vidět tak díky rozložení dat můžou disky fungovat absolutně nezávisle na sobě.
Data NEjsou jako u ostaních systémů RAID rozložena tak, že následující blok je na následujícím disku. Takový systém je sice tolikrát rychlejší než 1 disk kolik je v něm disků ( 5 disků - 5*rychlejší operace (čistě teoreticky)), ale má to bezpečno
stní nevýhody. Disk nemůže fungovat samostatně protože data jsou rozložena + pokud dojde k výpadku více než dvou disků je konec protože data všech ostatních disků nedávají smysl - jsou kompletně ztracena.
Naše uložení dat je MÉNĚ výkonné, ale je mnohem bezpečnější. Každý disk je autonomní, má svoje data na ostatních nezávislá. Může fungovat jak sám tak ve strivacím systému - striping se může zapínat/vypínat po přebootování. Je to vlastně tak, že k
dyž máte v počítači dva disky, můžete tam přidat paritní, zapnout striping file sytemu a od té chvíli jedete bezpečně. Pak paritní disk vyndáte a systém funguje dál. Největší přínos stripingu v tomto modelu je ten, že pokud se vyskytne na některém z dato
vých disků badsektor o data nepřijdete, protože ty se pomocí parity dopočtou.
Vlastnosti:
-
stripovací jednotka je oblast - nemusí to tedy být celý fyzický disk. Swapovací oblasti tedy nepodléhají stripingu a systém zbytečně nebrzdi.
-
stripovací oblasti musí být stejně velké
-
stripovacích datových oblastí může být teoreticky libovolný počet ( paritě je to jedno ).
-
overhead: (1/počet datových disků+1)*100 procent. Čím více disků, tím menší overhead.
-
při výpadku jednoho z datových disků se dopočte jeho obsah z ostatních datových disků a disku paritního.
-
při výpadku paritního disku se nikam nepočítá parita - systém je bez zabezpečení.
-
výpadek 2 a více disků. Vypadá to sice nepravděpodobně, ale stát se to může. Disky mohou začít fungovat odděleně. Obsah 2 disků je ztracen, obsah ostatních disků je zachován.
-
BADSECTORY na discích a jejich souvislost se stripingem.
-
BADSECTOR na datovém disku: obsah sektoru se dopočte z ostatních datových disků a disku paritního. Do vyšší vrstvy se ohlásí, že se sektorem nelze pracovat, ale že data byla zachráněna. Opravená data se pošlou do vyšší vrstvy, v bitmapě se sektor označ
í jako full. Parita se nyní počítá tak, že pokud sektor nelze pro výpočet parity přečíst, nahradí se pro výpočet jeho obsah 0x000... a takto se parita vypočte.
-
BADSECTOR na paritním disku. Celé patro ( datové sektory ze kterých se parita počítala ) se postupně musí prohlásit za neplatné. Prázdné sektory se označí jako full a poznačí se, že jsou bad ( i když to není pravda ). Použité sektory: kdykoli si vyšší vr
stva řekne o data z tohoto levelu, ohlásí se, že datový SEKTOR je bad ( i když to není pravda ) a že data byla zachráněna. Tím se postupně data z postiženého levelu přesunou jinam.
Nic lepšího jsem nevymyslel. Podle mého názoru je nesmysl po výpadku paritního sektoru dohledávat, kterému filu sektor patří a přealokovávat ho - to by bylo časově neúnosné. Takto se ale může stát, že se nepoužívané sektory nepřesunou.
Režijní struktury
Struktury, které drží seznam stripovaných oblastí, stav stripingu a vůbec vše důležité co se ho týká jsou deklarovány v CACHESUP.H.
//---------------------------------------------------------------------------------
//- STRIPING STRUCTURES - STRIPING STRUCTURES - STRIPING STRUCTURES -
//---------------------------------------------------------------------------------
struct _StripItem : PriQueueItem
{
byte Device;
byte Party;
dword Begin; // logical HD sector 0..
dword End; // logical HD sector 0..
dword Number; // End-Begin+1 ( data devices )
byte Type; // PARITY_STRIP || DATA_STRIP - used for table on disk
};
typedef struct far _StripItem StripItem;
class far DataStripsQueue : public PriQueue
{
public:
DataStripsQueue( void ):PriQueue() { return; };
void Insert( StripItem far *Item );
StripItem far *FindFirstParty( void );
StripItem far *FindNextParty( StripItem far *Actuall );
bool IsInStripingArea( byte Device, dword Logical );
void Show( void );
word DeleteParty( byte Device, byte Party );
word WriteSingleTable( byte Device, byte Party );
word WriteTablesToPartys( void );
// these two functions would be methods of StripSession
// but here is easier implementation
bool IsStriped( byte Device, byte Party ); // checks ParityHD too
word WriteSingleOffTable( byte Device, byte Party );
word WriteOffTablesToPartys( DataPartysQueue far * DirtyDataPartys );
~DataStripsQueue();
};
struct far _StripSession
{
byte StripingIs; // ON / OFF
DataStripsQueue DataHDs; // data HDs queue
StripItem ParityHD; // parity HD
};
typedef struct far _StripSession StripSession; // static structure in stripe.cpp
Struktura StripSession obsahuje flag zapnutí / vypnutí stipingu a frontu deskriptorů stripovaných oblastí a deskriptor paritní oblasti. Jak si můžete všimnout v deskriptorech, striping se orientuje podle logických sektorů na device ( nikoli na partyšně )
. Deskriptory jsou také používány jako položky stripovacích tabulek na disku.
Inicialize stripingu
Následuje popis toho co se děje při startu systému se stripingem. Implementace je v STRIPING.CPP, co která funkce dělá poznáte podle názvu nebo podle komentáře pod hlavičkou v místě implementace funkce.
Algoritmus:
1) Předchozími operacemi jsou v paměti připraveny fronty CLEAN a DIRTY oblastí ( ve funkci FSOpenFileSystem() z INIT.CPP ) . Nyní se nacházím ve funci InitializeStriping() STRIPING.CPP.
2) Beru oblast po oblasti a hledám na nich konfigurační tabulky stripingu.
3) Vezmu tedy z fronty první dosud nezkontrolovanou oblast. Pokud jsou všechny oblasti zkontrolovány GOTO 8)
4) Pokud na ní tabulka neexistuje beru z fronty další oblast GOTO 3). Pokud tabulka existuje GOTO 5)
5) Provede se analýza tabulky. Pokud je v ní "striping on this device OFF" GOTO 3) jinak GOTO 6)
6) Je to první nalezená tabulka? ANO - uložím si ji do speciálního bufferu. NE - porovnám ji s první nalezenou tabulkou a nastavím si podle toho flag FOUNDED_TABLES_ARE_SAME ( TRUE/FALSE ).
7) Všechny tabulky byly načteny. Nyní se podle první načtené tabulky testuje, které oblasti z ní skutečně existují a které v systému nejsou. Pokud oblast je uvedena v tabulce a v systému není zvýši se počítadlo mrtvých oblastí ( Dead++ a zapamatuje se ty
p oblasti )
8) Dead==0 a tabulky stejné - striping se nahodí v normálním módu - KONEC
9) Dead==1 a typ mrvé oblasti je RFSData - nahodí se rescue utilita, která provede záchranu ztracené oblasti do oblasti jiné. Viz. níže. Po této akci se ještě nahodí rekonfigurační utilita, kde má uživatel možnost ještě session doladit. Po rekonfiguraci
- KONEC.
10) Dead>=2 nic nelze zachránit. Dvě a více mrtvých oblastí to je moc. Jediné co zbýva je rekonfigurace sešny. Po rekonfiguraci - KONEC.
Setup utility
Konfigurační mód se nabídne uživateli při startu systému. V něm má možnost přidávat, ubírat a měnit seznam oblastí na kterých bude striping probíhat. Striping zde lze zapnout/vypnout. Lze také vypsat informace o jednotlivých oblastech. Po aktualizaci sez
namu se provede přepočet parity na paritním disku ( pokud je striping zapnut ).
Rescue utility
Implementace je v STRIPING.CPP. Ve funkci StripingRescue() se provádí nastavení a záchranu provádí funkce STRIPRescueParty().
Pokud jsme přišli o jednu datovou oblast nic se neděje. Jsme totiž schopni ji z parity a zbylých datových oblastí zrekonstruovat.
Záchrana jednotlivého sektoru se provádí takto.
Načtu si z paritního disku sektor s paritou. Potom jednotlivě načítám sektory z datových oblastí a vždy provádím XOR se sektorem parity. Nakonec mi zbyde v bufferu kde jsem měl uloženu paritu obsah ztraceného sektoru.
Záchrana oblasti.
Provede se záchrana Boot Recordu. Načte se Boot Record oblasti kam zachraňuji. V tomto boot recordu se změní informace jako adresa FNODU root direktoráře, počet grup v oblasti, počet rezervovaných sektorů na informace zachráněného Boot Recordu. Zbytek se
ponechá tak jak je a Boot Record se zapíše. Obdobná operace se provede záchrana The Second Boot Recordu. Zbytek oblasti ze zrekonsruuje jak bylo uvedeno v odstavci o záchraně jednoho sektoru.
Čtení a zápis sektorů ve stripovacím módu
Jak již bylo výše uvedeno, striping se orientuje na úrovni logických sektorů na device. Proto výběr toho, která funkce se použije ( klasická nebo stripovací ) se provádí ve funkci pracující na této úrovni. Všechny výše postavené moduly volají tuto funkci
a ta už provede výběr za ně. Zde je kód čtecí funkce ( zapisovací je analogická ) z STRIPING.CPP, který myslím vysvětlí více než dlouhý popis.
word ReadLogicalSector( byte Device, dword Logical, void far *Buffer, byte Number )
// this function is used by upper level
{
#ifdef DEBUG
printf("\n READing sector %lu... ", Logical );
#endif
if(
StripingSession.StripingIs==ACTIVE
&&
StripingSession.DataHDs.IsInStripingArea( Device, Logical )
)
{
#ifdef DEBUG
printf(" STRIPing version...", Logical );
#endif
return STRIPReadLogicalSector( Device, Logical, Buffer, Number );
}
else
{
return CLASSICReadLogicalSector( Device, Logical, Buffer, Number );
}
}
STRIPReadLogicalSector() je tedy funkce, která provádí čtení ve stripovacím módu. Čtení probíhá takto. Načítají se odpovídající sektory z jednotlivých datových oblastí a počítá se parita levelů. Nakonec se parita zkontroluje a případně opraví. Načtená da
ta se nakopírují do bufferu volající funkce.
STRIPWriteLogicalSector() provádí zápis. Zápis probíhá takto. Načtou se data z jednotlivých datových oblastí a spočítá se jejich parita KROMĚ OBLASTI DO KTERÉ BUDU ZAPISOVAT. K paritě se připočtou zapisovaná data. Následuje zápis dat a hned po něm zápis
parity.
Pro podrobnosti nahlédněte prosím do zdrojového kódu.
Pár slov k implementaci jako takové
Striping je místo, kde se nejvíce projevilo, že provádíme implementaci našeho file systemu pod DOSem. Při implementaci jsem musel velmi šetřit pamětí a tak jsou přepočty dělány po sektorech ( a tedy velmi hloupě ). Z toho plyne, že záchrany, přepočty par
it i běh je velmi pomalý. Do bufferů se data z jednotlivých disků čtou po sobě. Pokud by jsme systém implementovali pod UNIXem forknul by jsem si na každé čtení jedno vlákno a čtení by probíhalo paralelně ( tedy tolikrát rychleji než při normálním čtení
kolik je datových disků ( v naší implementaci díky sekvenčnosti je ale tolikrát pomalejší )). Na implementaci stripingu se tedy prosím dívejte spíš jako na špatnou implementaci snad dobrých nápadů, které by jinde mohly být implementovány mnohem lépe.
Díky za pochopení.
CacheMan = Cache + Swap, package, konzistentní zápisy
Naším cílem je zachování konzistence souborů. Proto data se kterými se bude pracovat zorganizujeme do logických celků - packageů. Zhruba řečeno, při práci s daty souboru RD/WR vyšší vrstva na vlastní žádost získá nějaké PackageID. Při všech dalších opera
cích nad tímto souborem bude používat tuto identifikaci. Spodní vrsta tedy bude vědět, která data k sobě logicky patří. Na konci práce se souborem nebo ve chvíli, kdy bude horní vrstva vědět, že byla všechna potřebná data "zapsána", zavolá horní vrstva C
ommitPackage( PackageID ). Na to provede spodní vrstva "double write" což je zápis, který zaručuje konzistenci. Ten se provede tak, že se obsah cache zapíše do odkládací oblasti, tato skutečnost se zapíše do logu a následně se kompletní package nakopíruj
e do cílového souboru.
V připadě havárie tedy bude možné operaci dokončit.
Konzistentním zápisům bylo nutné podřídit především cacheovací mechanismus. Museli jsme navrhnout cache tak, aby ji vyšší vrstva měla přehled o tom CO JE SKUTEČNĚ ZAPSÁNO NA DISKU A CO JE POUZE V CACHE. CacheMan se skládá ze dvou částí:
(i) paměťová část: klasická paměťová cache
(ii) odkládací část: pokud dojde paměť v paměťové části cache, musí se dirty data odložit na swapovací oblast konzistentních zápisů. Nelze je zapsat přímo do souboru - nevím totiž jestli uživatel zapsal do vše co chtěl.
Schema CacheMana:
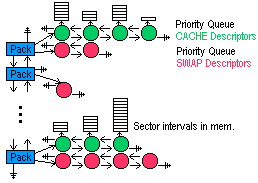
Pro cacheování jsme si zavedli package. Je to způsob jak předává horní vrstva cache informaci o tom, že určitá data k sobě logicky patří. Díky tomu cache ví, jak má data do souboru zapisovat, aby zůstal v konzistentním stavu.
Typicky při otevření souboru zažádá vyšší vrstva o vytvoření package ( package můžou být jemnější, třeba několik na jeden soubor). Vytvoří se struktury v cache a cache vrátí horní vrstvě číslo vytvořeného package. Potom kdykoli ze souboru vyšší v
rstva data čte/zapisuje odkazuje se na ně tímto číslem. Tato data, buď zústávají v cache nebo se odkládají na swap. Do souboru se uloží až po zavolání
CommitPackage( PackageID ). Tak má vyšší vrstva kontrolu nad tím co je v cache a co je ve skutečnosti na disku.
Pracuje se vždy s intervaly sektorů. Operace jsou navrženy tak, že package nikdy neobsahuje sektor dvakrát. DOKONCE PLATÍ ŽE V CELÉM CACHEOVACÍM SYSTÉMU MUŽE BÝT SEKTOR NEJVÝŠE JEDNOU!. Buď sektor v CacheManovi není, nebo je pouze v cache, nebo j
e pouze na swapu. Nyní popíši jak se postupuje při jednotlivých operacích:
Čtení
Dostanu číslo package, ke kterému se čtení vztahuje - PackageID. Vytvořím si bitmapu pro interval sektorů, který čtu ( čtu je do userbufferu ). Bit v bitmapě odpovídá sektoru v userbufferu. Kdykoli načtu sektory, nastavím odpovídající bity na 1. Končím k
dyž jsou všechny bity nastaveny na 1 - všechna data byla načtena.
Postup:
a) prohledám swap. Procházím swap descriptory package PackageID a čtu data do userbufferu a značím v bitmapě ( interval sektorů který mám načíst se částečně nebo úplně překrývá s intervalem na swapu ). Poznámka: když se data dostala na swap, znamená to ž
e jsou dirty - proto s nimi začínám. Projdu celou frontu swap deskriptorů package PackageID.
b) procházím cache. Procházím cache descriptory package PackageID. Pokud se interval sektorů který mám načíst částečně nebo úplně překrývá s intervalem na v cache kopíruji data do userbufferu a značím v bitmapě. Projdu celou frontu cache deskriptorů.
c) pokud ještě chybí nějaké sektory, natáhnu je přímo ze souboru.
Pokud je dost paměti umístím natažená data do cache mojeho package.
Zápis
Dostanu číslo package, ke kterému se zápis vztahuje - PackageID. Vytvořím si bitmapu pro interval sektorů, který budu zapisovat. Bit v bitmapě odpovídá sektoru v userbufferu ze kterého zapisuji. Kdykoli zapíši sektory, nastavím odpovídající bity na 1. Ko
nčím když jsou všechny bity nastaveny na 1 - všechna data byla zapsáno. ZDE SE DATA ZAPISUJÍ POUZE DO CACHEMANA NE DO SOUBOURU ( TO PROVÁDÍ AŽ COMMIT PACKAGE! )
Postup:
a) prohledám swap package PackageID. Na swapu jsou pouze dirty data, proto je musím přepsat jako první. Procházím swap descriptory a zapisuji data při částečném či úplném překrytí intervalů na swap a značím v bitmapě. Projdu celou frontu swap deskriptor
ů.
b) procházím cache package PackageID. Procházím cache descriptory. Pokud se interval sektorů který mám zapsat částečně nebo úplně překrývá s intervalem na v cache, kopíruji data do cache + v markuji jako dirty + značím v bitmapě. Projdu celý frontu cach
e deskriptorů.
c) pokud ještě chybí nějaké sektory zkusim:
(i) pokud je místo v cache - vytvořím desckriptor, data nakopíruji tam + omarkovaji descr dirty + poznačím v bitmapě.
(ii) pokud není místo v cachu zkusím swap. Analogicky.
(iii) pokud není místo na swapu následuji zápis přímo do souboru - PORUŠUJE KONZISTENCI.
Velikost cache, swapovací oblasti
Zde je myslím už celkem vidět jak systém funguje. Záleží tedy na uživateli jak velkou si zvolí cache a jak velkou odkládací oblast. Čím větší budou tyto oblasti tím lépe budou konzistentní zápisy fungovat ( větší objem dat, větší soubory ). Pokud bude ca
che dostatečně velká, uštří se čtení ze swapu - systém bude rychlejší.
Vše je tedy na uživateli. Čím bude velkorysejší, tím rychleji a lépe bude vše fungovat.
Commit package
Provede konzistentní zápis do souboru.
a) prochází se cache descriptory package PackageID.
- NOTDIRTY položky se dealokují.
- DIRTY položky se ukládají na swap a ponechávají se v paměti ( při jejich zápisu do filu se totiž později UŠETŘÍ jeden read - nemusí se číst ze swapu, ale zapíšou se rovnou z paměti. Tento postup je korektní, protože pokude vypadne proud tak se po res
tartu ze swapu dočtou... ). Jejich seznam se zapisuje do logu.
Pokud je swapování vypnuto nic se na swap samozřejmě nekopíruje a data se "nekonzistně zapisují přímo do souboru".
b) prochází se swap descriptory package PackageID. Seznam intervalů se připíše do logu.
c) prochází se podruhé swap descriptory a kopíruje se ze swapu do filu, descriptory se následně dealokují.
Pokud dojde v tomto místě k výpadku proudu nic se neděje. Po restartu systému se udělá REDO: podle logu se ze swapu data znovu zkopírují do souboru - KONZISTENCE JE ZARUČENA ( na swapu jsou nyní již všechna data - i z cache! ).
d) prochází se podruhé cache descriptory a data se z cache kopírují do souboru, descriptory se následně dealokují ( je to korektní a rychlejší - viz. výše ).
e) do logu se zapíše COMMIT a logovací file se smaže.
Byly tu i jiné možnosti...
Místo double writes přicházela ještě druhá možnost jak provést konzistentní zápis: zapsat data z cache někam do datové oblasti, zapsat to do logu a pak začít přepojovat odkazy na sektory v FNODEu ze starých na nové aktuální sektory. Pro tuto možnost jsem
se nerozhodl protože:
- Docházelo by k velké fragmentaci dat. Se zaplňováním file systemu by už data nebyla u sebe ( připomínám, že horní vrstva si může říci za kterým sektorem chce nové sektory naalokovat, spodní vrstva se potom snaží alokovat co nejblíže tomuto sektoru ),
natož v té samé grupě. Ve výsledku by to, podle mého názoru, bylo méně výkonné než poměrně rychlé souvislé zápisy ( méně seekování ).
- Swapovalo by se mezi data
- Problém by šel mnohem hůře rozdělit na horní a spodní vrstvu tak jak je tomu nyní. Spodní vrstva by totiž musela hrabat ve strukturách vrstvy horní a vice versa.
Funkce CacheMana jsou deklarovány v CACHEMAN.H, dále jsou využívány funkce podpory cache CACHESUP.H, kde jsou deklarace package a režijních struktur...
TRANSAKCE a LOGY : *.ALF, *.NOT, *.OKA, *.HLP, *.CML
Logy jsou páteří transakčního systému RFS ( jestli mu tak lze říkat ).
Nejdříve po jednom popíši jednotlivé logy. Pokud chcete jejich strukturu do podrobna zkoumat nebo Vás zajímá implementace => nahlédněte prosím do zdrojáků. Později v kapitole o tom co a jak se pomocí logů opravuje vyjasním jejich konkrétní význam a v
ěci jako jak se logy využívají navzájem a jaké jsou jejich vztahy.
*.ALF - ALLOC/FREE log
Je základním typem logu. Většina ostatních logů na něm stojí. Jeho vyjímečností je to, že se v jedné oblasti může vyskytovat nejvýše jeden. Je to z důvodu serializace transakcí. Existence nejvýše jednoho ALF logu mi zaručuje, že transakční operace budou
prováděny pořadě.
Tento log je používán funkcemi CacheManAllocateSector() a CacheManFreeSector(). Tyto funkce volají fci AllocFreeUsingLog() ( RECOVERY.H ). Tato fce má zásadní význam. Provádí totiž konzistentní zápis bitmapy. To znamená, že tr
ansakčně pomocí logu ALF provede změny ve statistikách a zápis bitmapy tak, aby vše odpovídalo a úspěšnou alokoci rovněž transakčně zaznamená do OKA ( OK Allocated log - viz. níže ) logu package. ALF record se při crash vždy ROLLBACKUJEuje ( Undo
AlfLog() z RECOVERY.H )=> nikdy se neprovádí redo ( nicméně jeho struktura je navržena tak, že by redo šlo z informací v něm obsažených provést ). Další důležitou vlastností ALF logu je, že operace jeho rollbacku je IDE
MPOTENTNÍ tzn. dojde-li v době rollbacku ke crash může se celá operace rollback provést znovy přes již jednou provedený a vše bude OK.
Struktura ALF logu ( pro detaily nahlédněte do zdrojáků )
// Log structure: Size: Off:
//
// LOG_BEG_TRANSACTION ( 0 Alloc, 1 Free ) 8 0
//
// LOG_BEG_WR_BMP 8 8
// write_to_log GroupID 4 16
// write_to_log Logical 4 20
// write_to_log LogicalInBmp (0-4095) 4 24
// write_to_log Number 2 28
// write_to_log Bitmap 512 30
// LOG_CHECKPOINT 8 542
// write_to_party Bitmap ..
// LOG_COM_WR_BMP 8 550
//
// LOG_BEG_WR_GRPSTAT 8 558
// write_to_log OldGrpFreeSpace 2 566
// LOG_CHECKPOINT 8 568
// write_to_party NewGrpFreeSpace ..
// LOG_COM_WR_GRPSTAT 8 576
//
// LOG_BEG_WR_SCND_BOOT 8 584
// write_to_log OldPartyFreeSpace 4 592
// LOG_CHECKPOINT 8 596
// write_to_party NewPartyFreeSpace ..
// LOG_COM_WR_SCND_BOOT 8 604
//
// LOG_BEG_WR_OKA 8 612
// ( call function ... which writes it transactionaly to OKA ) ..
// LOG_COM_WR_OKA 8 620
//
// LOG_COM_TRANSACTION 8 628
// ---------
// Total: 636
Vlastností kterou se liší od ostatních logů stejnou strukturou jako je NOT je to, že je vytvářen pouze pro alokace v nějakém Package ( připomínám, že při práci s cache se na package odkazuje při operacích loadtocache/load/save/alloc/free/commit ).
Tedy package ID je pozpodmínečně nutné pro jeho vytvoření.
*.NOT - NOT PackageID Alloc/Free log
Tento log má absolutně stejnou strukturu jako ALF log. Liší se od ALF logu tím, že je vytvářen při alokacích mimo package. Příkladem použití takový alokoací je alokace místa pro logy. Logy jdou mimo cache -> zápisy i čtení z nich se provádějí přímo -&
gt; nevyrábí se pro ně package protože nemá smysl provádět commit když cache nic z nich nesmí obsahovat. Na NOT logu se Vždy provádí operace ROLLBACK, která je IDEMPOTENTNÍ. Rollback se provádí funkcí UndoAlfLog() z RECOVERY.H
).
*.OKA - OK Allocated/Released log
Log OKA slouží pro evidenci naalokovaných/uvolněných sektorů toho kterého package. Každý package má vlastní OKA log. V průběhu práce se allokace/dealoakace v package provádějí přímo ( neodkládají se ). Pokud dojde ke crash před commitem musí být takové m
ísto uvedeno do původního stavu. Jak už bylo výše uvedeno, tyto operace se provádějí pomocí ALF logu, který připisuje do OKA logu ty úspěšné. Při crash se tedy provede rollback OKA zpětnou analýzou ( podrobněji níže ) a vše se uvede do původního stavu. V
rámci commitu se provádí mazání OKA logů - to je ta lepší možnost. Uvnitř commitu se v určité době už najisto ví ( viz níže ), že místo bude použito -> OKA log se může smazat. Do OKA logu se připisuje nakonec. OKA log se skládá z recordů této struktury:
typedef struct
{
dword Record_Beg; // ALLOC_RECORD || FREE+RECORD
dword State; // NORMAL_STATE || ROLLBACKED_STATE
dword Logical;
word Number;
dword GroupID;
dword LogicalInBmp;
dword Record_End; // OKA_RECORD_END
}
OkaRecord; // sizeof()=26
Podrobnosti RECOVERY.CPP.
*.HLP - HeLP Alloc/Free undo log
Tento log má absolutně stejnou strukturu jako ALF log. Je používán při rollbacku OKA logu. Jak se provádí rollback OKA logu je popsáno níže.
Podrobnosti RECOVERY.CPP.
*.CML - Commit undo/redo log
CML je log, který se používá pro zajíštění konzistence commitu určitého package( připomeňte si jak se provádí commit ). Během commitu se do CML uloží, kde je obsah cache na swapu ( určeno pro double write ), kde je odložen zbytek na swapu ( obsah swap de
scriptorů ). Jakmile se do commitu zapíšou všechny tyto informace, uloží se tam checkpoint, který říká "to byl poslední záznam, teď začínám kopírovat ze swapové partyšny na datovou". Ano zde je ta chvíle pro smazání OKA logu. Jakmile se uloží tento check
point, už se bude dělat po crash vždy REDO -> místo bude každoupádně použito a tak tedy každopádně nebudu rollback OKA potřebovat. Pokud dojde ke crash před zapsáním magiky provádí se vždy UNDO - nestihl se dostat obsah package/cache do odkládací obla
sti celý - takový zápis do datové oblasti by nebyl konzistentní.
Nyní se vždy podle CML logu načtou data ze swapu, uloží se do datové partyšny a místo na swapu se odalokuje ( ano pomocí ALF logu ). Mám tedy jistoto, že bude vše konzistentní. Provedení jak REDU tak UNDO podle CML logu je IDEMPOTENTNÍ ( Zarazila vás víc
enásobná dealokace na v připadě crash při opravách - po recovery se provádí přeformátování swapovacích oblastí. Testy jsem zjistil, že od zaplnění oblasti kolem půlky kapacity je to rychlejší než zvláštní log a dealokace dle něj ).
Struktura CML logu ( RECOVERY.H):
// Structure of CML record:
//
// TypeOfRecord // CACHE_INTERVAL || NOT_LAST_RECORD ( SWAP ) || BEGIN COPY
// Device; // 0, ..
// Party; // 1, ..
// SwapDevice;
// SwapParty;
// Logical;
// LogicalSwap;
// Number
//
//
// Structure of CML log file:
// Type
// CACHE_INTERVAL // intervals moved in pack commit from cache to swap
// ..
// CACHE_INTERVAL // intervals moved in pack commit from cache to swap
// NOT_LAST_RECORD // intervals in pack commit time on swap
// ..
// NOT_LAST_RECORD // intervals in pack commit time on swap
// BEGIN_COPY // checkpoint: all data on swap, begin of copy
// // from swap party to data party
Co se děje při inicializaci RFS
Pro otevření RFS slouží funkce FSOpenFileSystem() z INIT.CPP.
Co se děje při startu systému:
Testuje se zda jsou v systému přítomné fyzické disky. Fyziké disky se berou popořadě, na každém disku se načte MBR, podle něj se čtou všechny BR, které jsou použity. V těchto boot recordech se hledá v BR.OSID.ID magic "RFSData" nebo "RFSSwap". Pokud tam
tento magic je identifikuje se oblast jako oblast našeho file systemu. Oblasti se třídí do čtyř spojových seznamů.
V prvním jsou RFSData - tj. datové oblasti, které měly dirty flag nastaven na CLEAN ( ty jsou OK a s těmi už se nic dělat nebude)
Ve druhém jsou RFSData, které měly dirty flag nastaven na DIRTY - bude se muset provést jejich oprava.
Ve třetím jsou RFSSwap, které měly dirty flag nastaven na CLEAN. Ty jsou v pořádku.
Ve čtvrtém jsou RFSSwap, které měly dirty flag nastaven na DIRTY - bude se muset provést jejich oprava.
Takto se projdou všechna zařízení přítomná v systému a naplní se spojové seznamy.
Nyní se začne procházet fronta dirty RFSData na každou takovou oblast se zavolá funkce RecoverParty() z RECOVERY.CPP ( viz. níže ), která provede opravu oblasti. Po opravě se datová oblast přepojí do spojáku CLEAN dat
ových oblastí.
Takto se zpracuje celý DIRTY spoják datových oblastí.
Nyní se projde fronta dirty RFSSwap a každá oblast z něj se zformátuje. Data, která na nich byla už z nich dostala funkce RecoverParty(). Nyní se tedy pouze musejí pročisti a rychlý formát je tou nejefektivnější metodou. Po přeformátování se odklá
dací oblast přepojí do spojáku CLEAN odkládacích oblastí.
Takto se zpracuje celý DIRTY spoják odkládacích oblastí.
V dalším kroku se provede nastavení dirty flagu všem oblastem ( které jsou nyní už pouze ve dvou CLEAN spojácích ).
Provede se nahození CacheMana
RECOVERY aneb jak se opravuje pomocí logů po pádu systému
Implementace všeho o čem zde budu psát je v RECOVERY.CPP.
V této kapitole dokumentace popíši co se začne dít, když se po restartu systému zjistí, že oblast je dirty a je ji tedy třeba uvést do konzistentního stavu užitím logů. Tento úkol plní funkce RecoverParty().
Co recovery v jedné oblasti dělá:
-
Jako první se vyhledají všechny *.HLP logy ( které mají stejnou strukturu jako *.ALF ). Tyto logy se generují, když se provádí rollback OKA logu. HLP log se vytvoří a musí být kompletní. Po jeho kompletním vygenerování se přejmenuje na *.ALF a za
volá se na něj funkce UndoAlfLog() z RECOVERY.CPP ) , která provede rollback jednoho OKA recordu z *.OKA logu ( to vše se provádí v rámci rollbacku OKA filu - NE NYNÍ - vyjasňuji pouze situaci vzniku HLP logu ). Zde se vš
echny HLP logy smažou. Mohu to udělat protože budou v pozdější fázi recovery vygenerovány znovu. Ještě bych rád ujasnil, že pokud někde zůstane HLP log, znamená to že byl sice vygenerován, ale nebyl přejmenován a nemohlo se tedy ani začít s jeho roll
backem - ničeho se nemusím bát když ho mažu.
-
Nyní se vyhledávají *.NOT logy. Tyto logy jsou používány funkcemi pro alokaci a uvolňování sektorů operací, které nejsou cacheovány. Používají se například při práci s logy a s odkládacími oblastmi. Swap je na konci recovery naformátován takže o t
en se nemusím starat. Ale misto alokované/uvoněné v datové oblasti musí být uvedeno do původního stavu - provede se tedy rollback NOT logu. Protože nebyla šance, jak změnu zaevidovat v FNODEu, protože než se operace skončila systém se složil. Kdyb
y jsem rollback neprovedl vzniky by mi ztracené sektory, které by nikomu nepatřily nebo naopak obsazené sektory, které by byly v bitmapě označeny jako prázdné.
-
Následuje vyhledání *.ALF logů jejich rollback a probublání skrz ně do jejich OKA filu ( z kterého byly volány ). Při rollbacku ALF file probublá do OKA a tam označí sobě odpovídající record jako rollbacked. Vše se provádí tak, aby v případě, že d
ojde ke crash nyní v době opravy se mohlo vše dokončit ( idempotence rollbacku ALF logu je známa ). Rollback ALF logů uvádí do konzistentního stavu ostatní log fily. Tím je myšleno to, že už v nich nejsou zlomky nějakých recordů, ale recordy celé - recor
dy jsou v nich buď typu commited nebo rollbacked.
-
Na řadě je oprava pomocí CML logů. Ty se vytvářejí v průběhu commitu jak bylo popsáno výše. Opravu pomocí CML logů provádí RecoverUsingCml() z RECOVERY.CPP
(i) pokud CML obsahuje magic BEGIN_COPY - provede se redo ( pokud došlo někdy dříve ke crash během této opravy může se stát, že se udělá některá z operací na swapu dvakrát, ale to nevadí , protože swap se v zápětí reformátuje ). OKA log tohoto package se
smaže ( pokud se tak již nestalo, protože je jistota, že místo na swapu bude použito ).
(ii) pokud CML magic BEGIN_COPY neobsahuje - musí se provést undo. To znamená, že CML se smaže. Protože některá data jsou na swapu a některá ne a swap se reformátuje. Musí se však provést rollback OKA logu odpovídajícího package, protože by v datové obla
sti zůstalo místo na které se se volalo alloc/free a nebude využito.
-
Teď už zbyly v oblasti pouze OKA logy. Na tyto OKA logy musí být provedena operace ROLLBACK. Tu provádí funkce RollbackOkaLog() z RECOVERY.CPP. Ta funguje takto:
Poslední záznam v OKA logu nemusí být analyzován, protože byl označen jako ROLLBACKED při undo korespondujícího ALF logu. Zbývá tedy analyzovat zbývající, již kompletní recordy OKA logu. Recordy se čtou od zadu logu směrem k počátku. Pro každý record se
vygeneruje ALF log. To se udělá tímto způsobem: nejdříve se vygeneruje HLP log funkcí GenerateHlpLog() z RECOVERY.CPP. který je potom přejmenován na *.ALF. Je to uděláno takto protože chci aby ALF byl vždy kompletní. Jestliz
e se system složí před rename - HLP file se smaže. Jestliže, se systém složí po rename vím, že recovery ALF zpracuje jako první, dále vím, že v oblasti může být nejvýše jeden ALF log ( ten můj ) a také vím, že provedení rollbacku nad logem ALF je idempot
entní -> vše je OK, po crash lze vklidu pokračovat v rollbacku.
Zpět ke zpracovávání recordů. Record se načte, podívám se na magic: jestliže je rollbacknutý, vezmu načtu předchozí, jestli že je NORMAL zpracuji ho. Jestliže je typu ALLOC vygeneruji alloc HLP log, jestliže je typu FREE vygeneruji free HLP log. Přejmenu
ji HLP log na ALF. Zavolám UndoAlfLog() která provede rollback za mě. Označím record v OKA jako rollbacked. Smažu OKA log.
Recovery práce jsou hotovy => oblast je opravena...
Co se děje při zavírání RFS
Pro uzavření RFS slouží funkce FSShutdownFileSystem() z INIT.CPP. Tato funkce nejdříve provede kompletní commit cache a tím dokončí všechny transakce. Potom projde jak spojík datových oblastí tak spoják odkládacích oblastí a vš
em oblastem nastaví dirty flag na CLEAN, který znamená, že oblasti byly odpojeny korektním způsobem.