Next: Zeštíhlování seznamu úspěšných rozkladů Up: Programátorské techniky Previous: Vlastnosti operátorové notace Obsah Index
Jak bylo již zmíněno, jazyky přijímané parsery v alternativní
kompozici obecně mohou být disjunktní. V těchto případech dochází
k neefektivitě. Celý problém si ukážeme na velmi jednoduchém případu
kombinátoru letter, v němž jsme v jeho původní definici použili
právě kombinátor <:>:
letter(W):-
W :->
lower <:> upper.
Zamyslíme-li se nad tím, jak letter funguje například pro vstup
"a", tak zjišťujeme, že je nejdříve aplikován parser
lower. Až potud je vše v pořádku. Potom je však použit parser
upper, který neuspěje a dojde k navracení. Protože jazyky
přijímané parsery lower a upper jsou disjunktní, s naprostou jistotou víme, že kdykoli lower uspěje, tak již nemá
smysl parser upper aplikovat -- ten v takovém případě
vždy selhává.
V tomto jednoduchém případě je ztráta efektivity ještě malá, ale můžeme si představit mnohem komplikovanější alternativní kompozice množství parserů, jejichž aplikace již bude z hlediska časové složitosti nezanedbatelná. Kupříkladu:
prologProgram(W):-
W :->
(prologDirective
<:>
prologClause
<:>
prologComment) <**> .
Pokud uspěje parser prologDirective je jisté, že všechny zbylé
alternativy selžou. To platí rovněž v případě
prologClause. Výpočetní složitost aplikace jednotlivých parserů
v alternativní kompozici je v tomto případě již nezanedbatelná. Ve
většině iterací se tak plýtvá.
Nabízí se tedy otázka, zda by nebylo možné takovou přídavnou informaci nějakým způsobem využít v implementaci parserů. Umožní nám to následující dvě varianty kombinátoru alternativní kompozice:
<:(P1,P2,I+L):-
I+L_ :-> P1,
(L_=[] -> (I+L :-> P2) ; L=L_).
Kombinátor <: má charakter zkráceného vyhodnocení zleva. Pokud
uspěje parser
:>(P1,P2,I+L):-
I+L_ :-> P2,
(L_=[] -> (I+L :-> P1) ; L=L_).
Kombinátor :> je symetrickou variantou <:. Nejdříve tedy
aplikuje parser
Nyní definujme efektivnější variantu parseru letter vytvořenou
pomocí jednoho z právě zavedených kombinátorů:
letter(W):-
W :->
lower <: upper.
Výše uvedený parser vydává identické výsledky jako původní letter,
navíc však pracuje efektivněji.
Na základě právě vytvořených kombinátorů můžeme definovat nejen množství lépe fungujících parserů, ale také samotných konstruktorů.
V jejich vytváření pokračujme nyní parserem binárního čísla. Jeho vstupem je posloupnost nul a jedniček. Jako výsledek vydává odpovídající decimální hodnotu:
bin(W):-
W :->
(symbolA("0") <: symbolA("1"))<<*>>
<@ foldR(evalBin,0>0) => alter(Val>_,Val).
evalBin(I,Val>Pow,Value>Power):-
Power is Pow+1, Value is Val+(2^Pow)*I.
Variantu nově definovaného kombinátoru alternativní kompozice jsme
použili v parseru bin ve stejné situaci jako v letter.
Půjdeme ještě dál a představíme si zástupce nové rodiny iterátorů:
<*>(P,W):-
W :->
(P <&> P<*>)
<:
epsilon.
V původně použitém mutátoru <<*>> je v každé iteraci aplikováno
primitivum epsilon jen proto, aby byl jím vydaný výsledek
(kromě případu poslední iterace) oříznut v seznam úspěšných rozkladů
pomocí diamantu.
Iterátor <*> řeší ořezávání struktury LOS elegantnějším
způsobem -- zahazuje nepotřebné výsledky za běhu a postupuje nejpřímější cestou k maximální derivaci. V průběhu dalších
fází výpočtu se tak v případě zřetězení parserů nemusíme zdržovat
vytvářením výsledků o nichž dopředu víme, že je nebudeme
potřebovat. Druhá alternativa -- tedy epsilon, se uplatní
pouze jednou a to za poslední číslicí přijímaného čísla:
bin(W):-
W :->
(symbolA("0") <: symbolA("1"))<*>
<@ foldR(evalBin,0>0) => alter(Val>_,Val).
V knihovně jsou připraveny i varianty zbylých iterátorů -- jako
<+>, <?> a jejich varianty.
Důležitým přínosem nových konstruktorů je nejen výrazná úspora paměti, ale také větší efektivita výpočtu. Stejně jako s pomocí diamantových verzí lze s jejich pomocí udržovat velikost struktury LOS v přijatelných mezích. Navíc se nezajímavé výsledky ani nevytvářejí, jak jsme si vysvětlili výše.
Zároveň je na místě velká opatrnost při použití společně s parsery přijímajícími jazyky, jejichž průnik je neprázdný.
Jindy může být eliminace derivací žádoucí. Příkladem takové situace jsou identifikátory a klíčová slova programovacích jazyků.
Vezměme si například jazyk Java. Klíčová slova jsou rezervovanými
názvy identifikátorů (například new či for). V analyzátoru se pak použije konstrukce typu:
Pokud uspěje parser klíčových slovW :->...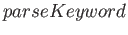
<: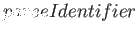
...
Jindy použití nových verzí kombinátorů v případech parserů s neprázdným průnikem sice může zrychlit výpočet a ušetřit paměť, zároveň nás však může připravit o důležité výsledky. Je tedy nutné věnovat dostatečnou pozornost návrhu parserů.
Až dosud jsme vytvořili několik rodin mutátorů pro iterativní aplikaci
parserů. Rodina iterátorů představená v této části je poslední a v mnoha ohledech nejlepší z nich. Počet definovaných iterátorů opět
narostl, proto jsou všechny přehledně shrnuty v tabulce ![[*]](crossref.png) .
.
dvorka 2013-12-31