Next: Iterace Up: Transformace syntaktického stromu Previous: Podpora mutátoru Obsah Index
V této části si představíme dva predikáty vyššího řádu, které umožní
zapisovat některé složitější operace na výsledcích přímo v parametru
mutátoru <@.
První z nich pokrývá potřebu následné aplikace několika operací.
Pomocí predikátu =>, jenž je definován rovněž jako operátor,
lze řetězit sémantické operace nad syntaktickými stromy:
Na syntaktický strom vydaný parserem je aplikována operace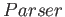
<@
=>
Obecně lze samozřejmě řetězit libovolný počet operací:
Syntaktický strom potom prochází celou kolonou predikátů<@=>...=>
Nově definovaný predikát => umožňuje efektivnější provedení
této konstrukce. Bez něj bychom museli výše uvedený případ
transformace v několika krocích implementovat výhradně s pomocí
mutátoru aplikace sémantické operace:
Takové zpracování obnáší<@<@...<@
=> jsou aplikovány všechny
operace v jednom kroku -- vždy tedy postačuje jediný průchod.
V úvodu zmíněný druhý predikát vyššího řádu je určený pro specifikaci
argumentů následujících za výsledkem pocházejícím ze seznamu úspěšných
rozkladů. Doposud bylo možné používat v parametru mutátoru <@ pouze
operace s rozhraním:
Kdy se za přímo specifikované argumenty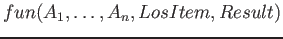
=> výstup parseru zavedeme predikát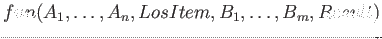
->>, který po jednom přidává parametry :-@/1 zavedeného v kapitole
![[*]](crossref.png) . Výsledky procházející kolonou -- nemusí tedy
být přímo vyhodnocovány, ale může dojít pouze k částečné aplikaci, kterou
lze uskutečnit i ve více krocích.
. Výsledky procházející kolonou -- nemusí tedy
být přímo vyhodnocovány, ale může dojít pouze k částečné aplikaci, kterou
lze uskutečnit i ve více krocích.
Predikát ->> je zaveden jako infixní operátor. Má nižší precedenci
tj. vyšší prioritu než =>:
Jeho použití je přínosné zejména při jeho vícenásobné zřetězené aplikaci -- jak je vidět na následujícím příkladu:<@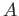
->>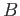
->>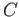
=>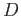
->>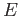
->>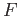
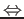
<@(->>->>=>(->>->>
kde aplikovaná sémantická operace odpovídá:<@
->>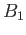
->>...->>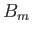
Oba nové operátory lze samozřejmě libovolně kombinovat. Tak například zpracování výsledku::-@![$[A_1, \dots, A_n,+LOS,B_1, \dots, B_m, -Result]$](img108.png)
odpovídá následující transformaci hodnoty<@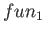
=>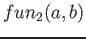
->>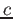
->>->>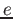
=>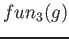
Kolony zčitelňují kód parserů a činí jej srozumitelnějším. Bohužel nejsou zpravidla tak efektivní, jako je použití explicitně definovaného jednoúčelového predikátu.
Hlavní uplatnění nacházejí v parserech generovaných online, kde hrají nezastupitelnou roli při transformacích syntaktického stromu.
Jsou přínosné i při přímém vytváření parserů na příkazové řádce interpretu, kde můžeme snadno, ať už pro ladící účely či z jiného důvodu, upravovat výstupní hodnoty parserů bez nutnosti přidávání nového predikátu do databáze.
Zvážení všech hledisek při použití kolon -- tedy zejména rozhodnutí mezi mírou elegance a efektivity, záleží pouze na programátorovi.
dvorka 2013-12-31