Next: Příklad: Up: Kombinátory parserů Previous: Kombinátory parserů Obsah Index
Nyní uděláme důležitou odbočku a budeme se věnovat operátorovému
zápisu a zavedení predikátu :->.
Jazyk Prolog poskytuje prostředky, pomocí nichž může programátor
zavést vlastní operátory a používat je při zápisu struktur. Výhody
operátorové notace jsou nesporné. Toto syntaktické pozlátko
umožňuje použití pro člověka výrazně čitelnějšího zápisu. My tuto
příjemnou vlastnost jazyka Prolog samozřejmě využijeme a nejdůležitější kombinátory a mutátory definujeme rovněž jako
operátory. Tím se otevře cesta ke způsobu zápisu parserů, který bude
velmi podobný deklarativní notaci gramatik. Navíc nám použití
operátorů umožní vytvářet efektivněji pracující parsery a jejich
konstruktory, jak se přesvědčíte v kapitole
![[*]](crossref.png) .
.
Prvním z predikátů definovaných jako operátor je právě kombinátor pro sekvenční kompozici.
Přehled všech zavedených operátorů je obsažen v příloze
. Příloha poskytuje přehledné informace o precedenci,
asociativitě a notaci jednotlivých operátorů a usnadňuje jak orientaci
mezi operátory, tak vytváření nových parserů.
Jako příklad použití kombinátoru sekvenční kompozice si ukažme
aplikaci parseru pro rozpoznání prologovského operátoru aritmetické
ekvivalence =:=/2:
?- <&>>(symbol("="),symbol(":") <&>> symbol("="),s("=:=")+L).
L = [s([])> (O'=> (O':>O'=))]
Yes
Úkolem výše uvedeného umělého příkladu je poukázat na fakt, že
nevystačíme pouze s definicí kombinátorů jako operátorů. Zatímco v druhém zřetězení parseru dvojtečky a symbolu rovnosti šlo použít
<&>> v infixní notaci a zachytit tím přehledně fakt, že
aplikací kombinátoru na parsery vzniká parser nový, v prvním případě
to možné nebylo. Příčinou vynuceného použití standardního zápisu je
to, že v dané situaci kombinátor provádí volání jím vytvořeného parseru,
a proto mu přibyl argument obsahující vstupně/výstupní term.
Naším cílem nyní je odstranit tuto nepravidelnost a umožnit
tak elegantnější a čitelnější zápis v operátorové notaci ve všech případech.
Pro řešení tohoto problému bychom mohli použít predikát :-@/1,
pomocí něhož bychom parser aplikovali. My však raději zavedeme pro
aplikaci parserů speciální predikát :->/2, který
navíc definujeme jako operátor, abychom tím zápis parserů udělali ještě
přirozenější. Jeho prvním argumentem je vstupně/výstupní term a druhým
parser:
Tento predikát se postará o připojení vstupně/výstupního termu a provede aplikaci parseru. Vyjádřeno schematicky, místo zápisu: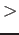
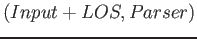
budeme používat ekvivalentní: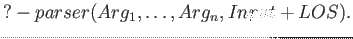
Tím se také vyjasňuje motivace spojení vstupního parametru a seznamu úspěšných rozkladů do jednoho termu v návrhu rozhraní parserů.
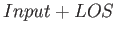

Vraťme se ještě zpět k příkladu, který stál na počátku a ukažme si konkrétní použití nového predikátu:
?- s("=:=")+L :->
(symbol("=") <&>> symbol(":") <&>> symbol("=")).
L= [s([])> (O'=> (O':>O'=))]
Yes
Použití predikátu :->/2 bude výhodné především v případech složitějších
parserů, ve kterých použijeme operátory různých priorit. Bez něj bychom
byli nuceni vyhledávat konstruktor, který má pečovat o vstupně/výstupní
term, a jeho standardním zápisem bychom narušovali jinak přehlednou
notaci.
Uzavřeme téma operátorové notace a obrátíme nyní svou pozornost zpět k Backusově normální formě a definujeme kombinátor parserů, který odpovídá operaci alternativní kompozice:
% <:>(+Parser1, +Parser2, ?Wrapper)
<:>(P1,P2,I+L):-
I+L1 :-> P1,
I+L2 :-> P2,
append(L1,L2,L).
Kombinátor pro alternativní kompozici aplikuje na stejný vstup
Důležitost kombinátoru <:> tkví především v tom, že umožňuje do
parserů vnést nedeterminismus. Pomocí kombinátoru alternativní
kompozice lze prozkoumat několik cest výpočtu. Jeho použití rozvětvuje
výpočet do dvou cest -- jedné parseru ![]() a druhé parseru
a druhé parseru ![]() .
Ukažme si to na definici velmi jednoduchého parseru pro rozpoznávání
písmen:
.
Ukažme si to na definici velmi jednoduchého parseru pro rozpoznávání
písmen:
letter(W):-
W :->
(lower <:> upper).
Parser letter aplikuje na vstup pomocí kombinátoru alternativní
kompozice dva parsery. Protože jak lower tak upper vrací
v případě úspěchu nejvýše jednu derivaci, také letter vydá
strukturu LOS nejvýše s jednou položkou neboť jazyky přijímané parsery
lower a upper jsou disjunktní.
Obecně však jazyky přijímané parsery ![]() a
a ![]() disjunktní být
nemusejí a můžeme tedy získat pro jednu sentenci hned několik
správných rozkladů. Tím se konečně vysvětluje i důvod zavedení
seznamu úspěšných rozkladů pro reprezentaci výstupu parserů.
disjunktní být
nemusejí a můžeme tedy získat pro jednu sentenci hned několik
správných rozkladů. Tím se konečně vysvětluje i důvod zavedení
seznamu úspěšných rozkladů pro reprezentaci výstupu parserů.
Předveďme si to na parseru pro přirozená čísla, který využívá nedeterminismu ve své rekurzivní definici:
nat(W):-
W :->
(digit <&>> nat
<:>
epsilon).
Při každém použití parseru nat je možnost ve výpočtu buď pokračovat,
pokud následují na začátku vstupu další číslice, nebo výpočet ukončit
pomocí primitiva epsilon, které vždy uspěje. Bez kombinátoru
alternativní kompozice by bylo možné vytvořit pouze parser pro nějaký
fixní počet položek, zatímco s ním můžeme definovat nat, který
přijímá přirozená čísla s dopředu neznámým počtem cifer. A ještě
příklad:
?- "256"+L :-> nat.
L = [s("")> (O'2> (O'5> (O'6>[]))),
| s("6")> (O'2> (O'5>[])),
| s("56")> (O'2>[]),
| s("256")>[]]
Yes
Získali jsme čtyři možné rozklady uložené v seznamu úspěšných
rozkladů. V příkladu si všimněme toho, že výsledky jsou dle
úmluvy uspořádány podle délky zpracovaného vstupu.
Dále se zde setkáváme poprvé s tím, že za některých okolností můžeme získávat kromě maximální derivace ještě nezanedbatelné množství dalších derivací, které nás ve skutečnosti nezajímají. První konstruktory řešící tento problém navrhneme již v následující části.
Protože už máme vytvořeny ekvivalenty dvou operací používaných v Backusově normální formě, můžeme si na příkladu převodu pravidla gramatiky ukázat, jak se nám podařilo realizovat to, co jsme si v úvodu této kapitoly předsevzali.
dvorka 2013-12-31