Next: Přenos stavové informace Up: Módy Previous: Módy Obsah Index
file/2. Jeho selektor má následující signaturu:
kde
s/1, které mohlo vypadat v úvodních kapitolách poněkud zbytečně --
s/1 je selektor módu pro zpracování vstupního textu
ve formě řetězce.
Informace potřebné pro inicializaci módu file/2
lze získat pomocí připravených predikátů openFile/3 (deskriptor)
a atStream/2 (pozice). Reprezentace vstupního textu musí
umožňovat elementární operace, viz ![[*]](crossref.png) . Ty jsou
zde realizovány pomocí predikátů
. Ty jsou
zde realizovány pomocí predikátů get0/1 a setStream/2.
Mód oživíme přidáním jediné klauzule do procedury item/1:
item(file(Sh,O)+L):-
setStream(Sh,O),get0(B),
(B=(-1) -> L=[]
; atStream(Sh,Oo),L=[file(Sh,Oo)>B]).
Jak jednoduché! Díky celkovému návrhu knihovny nyní stačí pouze
otevřít vstupní soubor a můžeme použít kterýkoli parser
pro jeho analýzu. Všechny dosud definované parsery a konstruktory
mají pouze implicitní klauzule tj. ty klauzule, které se
unifikují se všemi selektory a o reprezentaci vstupu se
nezajímají. Jediné primitivum item odebírá první položku
ze vstupu a jeho proceduru jsme právě doplnili.
Pro všechny často používané módy jsou navíc definovány predikáty s obecnou signaturou:
kde
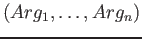
file/2 tedy můžeme
použít:
?- invokeFile('input.bnf',parserBnf,L).
Ještě se na chvíli zastavme u možností, které nám módy, co se týče
zdrojů vstupu, nabízejí.
Doplněním klauzule do procedury primitiva item můžeme analogickým
způsobem, jako jsme to učinili v případě módu file/2, doplnit
knihovnu o další typy vstupu.
Zajímavé může být například použití generátorů vstupu.
Primitivum item místo získávání vstupu z nějakého vnějšího zdroje
volá predikát generující vstup. Takovým typem vstupu je například
konstrukce streamů tak, jak ji známe z funkcionálního jazyka ML.
Elementární jednotkou vstupního textu nemusí být pouze dosud používané
ASCII kódy, ale můžeme si představit mód, ve kterém se ze souboru
načítá proud termů, který byl připraven lexikálním analyzátorem
(). A jistě existuje ještě celá řada
dalších možností.
dvorka 2013-12-31